Accessing Lab data via FHIR – part 4
May 30, 2021 1 Comment
In this final post for the lab series, we’ll take the terminology resources that we created in the previous post and use them to map codes from the laboratory bespoke coding system to the (mostly) LOINC based NZPOC set.
A quick reminder of what those resources were:
- A CodeSystem and ValueSet that held the descriptions of the bespoke lab codes
- A ValueSet for NZPOC, plus the CodeSystem for the non-LOINC codes.
- A ConceptMap that defined the mappings from lab code to NZPOC (and we’re assuming that all the bespoke codes could be mapped – in practice you’d need a strategy for codes that couldn’t be mapped.)
Let’s think about an architecture within which this could work. Here’s a simple picture.

It should be pretty straightforward. There are some labs to the left sending in lab results in the format of HL7 version 2 messages (an almost universal way of doing this). They pass through an integration engine which inserts them into the repository in whatever format the repository accepts. Could be FHIR resources, but more likely a database structure specific to the needs of the lab domain. And, conceivably doing more than just storing data – for example it could be tracking that the results have been viewed by the ordering clinician.
To the right is a client that is making FHIR REST queries against the repository as we’ve discussed in previous posts, and there’s a FHIR Façade (and / or API manager) converting the FHIR queries into repository queries and creating the FHIR responses.
Above them all is a Terminology Server.
So what, you ask, is a terminology server?
Well, the simple explanation is that it is a FHIR server (in that it exposes a FHIR interface) that specializes in terminology functionality. It has a copy of the terminology resources (CodeSystem, ValueSet, ConceptMap and others) and it also supports some of the terminology services (or operations).
There are a number of publicly accessible Terminology servers that you can use for experimenting – I generally use Ontoserver, as it allows resources to be uploaded, and supports a pretty complete set of terminology operations.
FHIR Operation?
A FHIR Operation allows a server to provide more complex services than basic RESTful updates and queries. For example, a common API that a number of servers supply is called $validate. The idea is that you send a resource instance (or what you think is a resource instance) to a server, and the server will tell you if the resource is conformant to the specification and/or one or more profiles. So, it ‘hides’ more complex logic behind the interface.
There are a number of ways of invoking an operation, and the inputs and outputs can also vary. Because of this variability, there’s a specific resource – the Parameters resource – which can be used as either an input or an output. It has no other purpose, and there is no [host]/Parameters endpoint.
The particular operation we’re going to use is the concept translation operation (or $translate) which uses a ConceptMap resource to translate a supplied concept (in the form of a code, Coding or CodeableConcept) into the equivalent concept/s as defined in the ConceptMap.
The output is a Parameters resource with a number of elements. Unfortunately, the contents of the Parameter is not standardized by the Operation Definition, so may well vary between servers. The one supplied by Ontoserver is shown below.
To test out the $translate operation, I followed these steps:
- I uploaded the ValueSets, CodeSystems and the ConceptMap I created for the example in the previous post to Ontoserver.
- I then used a REST client (Postman) to invoke the $translate operation as follows:
https://r4.ontoserver.csiro.au/fhir/ConceptMap/ClinFHIRLabToNZPOC/$translate?code=glu&system=http://clinfhir.com/ns/clinFHIRLab&target=http://clinfhir.com/fhir/ValueSet/NZPOC
As you can see, it is expressed against the ConceptMap instance, and needed the code we want to translate, and the target ValueSet where the target code (the result of the mapping) can be found.
The response was the following Parameters resource:

As you can see the translate operation was successful, returning a single Coding datatype with the mapped code from the ConceptMap.
When I re-tried with an unknown code, then the result parameter was false with a message to indicate that no mapping could be found.
Using the $translate operation on a server is the most flexible approach to perform CodeSystem mapping – any changes can be made by updating the required resources, and the mapping process can be much more complicated than this example). But for large volume mappings, performance is going to be an issue. These can always be addressed by appropriate design (eg caching) and hardware, but for simple mappings like this one, we can always resort to code.
The assumption is that the data in the repository contains a mixture of codes, so we need to get all the data and then perform the mapping on the client. It would, of course, be a lot better if this normalization was done before loading into the repository, if that were feasible.
Here are some code shots from an app I’m building to access lab data (I’m learning Vue as I go).
This code snippet reads the CodeSystem resource and builds a hash keyed on the source system and code, with the target system/code as the hash value. It saves the hash for later used as a property of the containing service code (we use it in the next snippet) and returns a simplified form for display.
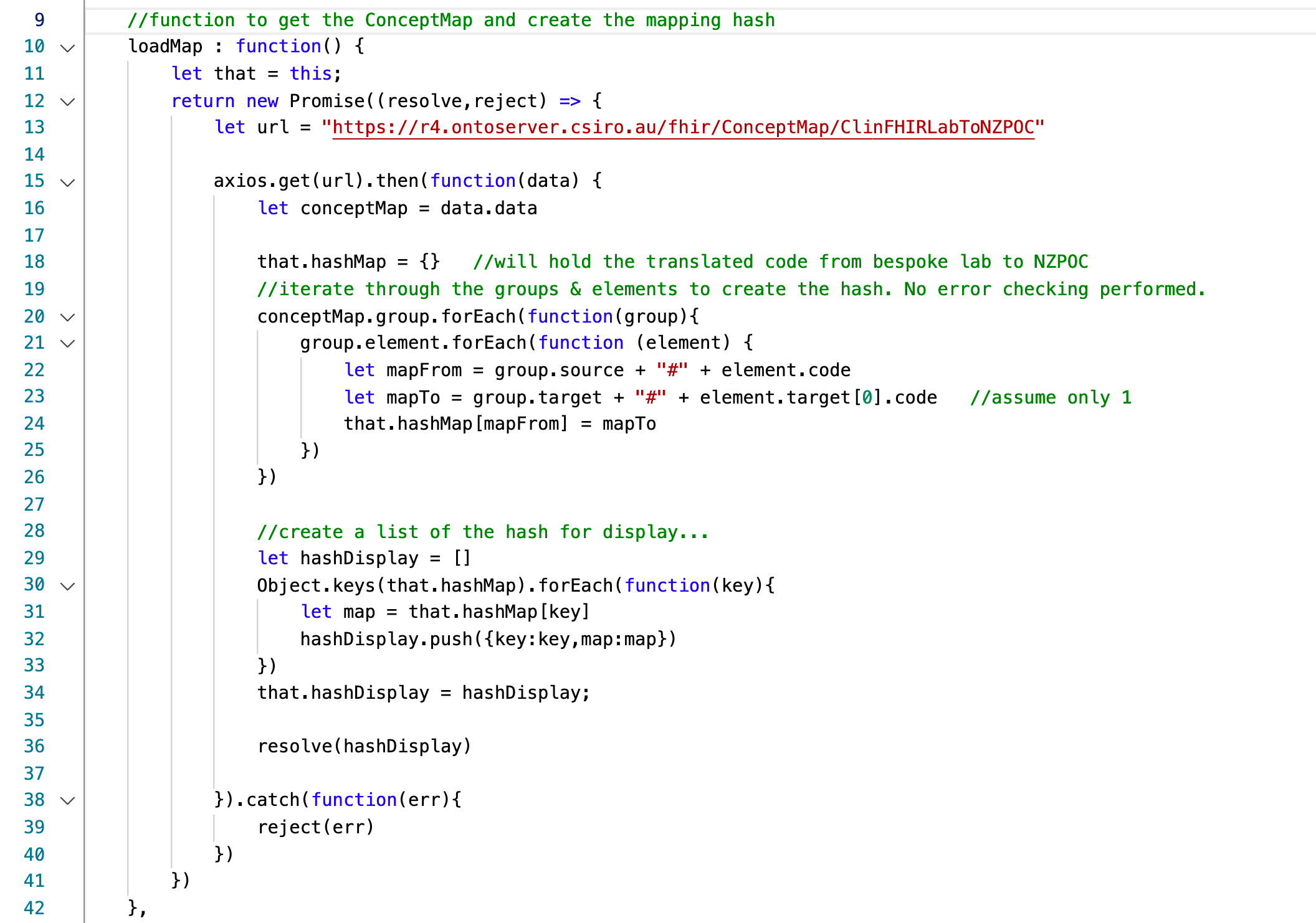
And here we are reading all the labdata for a patient, performing the conversion as needed:
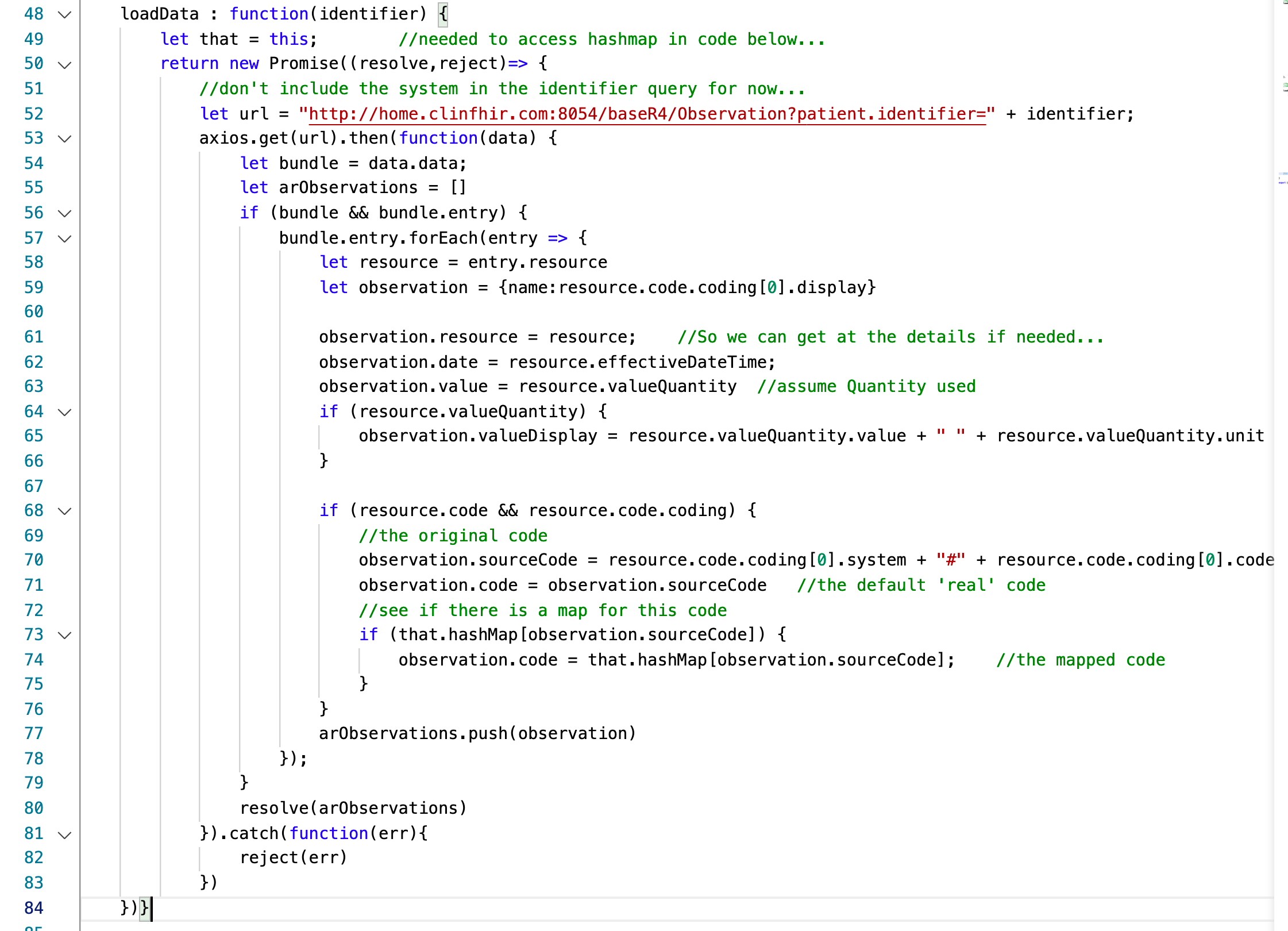
It will run extremely quickly once the hash has been created, and because it used the ConceptMap to generate the hash in the previous step, it can be easily updated by updating the ConceptMap on the server. (Though you’d have to know to re-load it when that happens of course)
Now this is of course an application specific solution. It works for this specific – and rather simple – Use Case, and this Use Case alone. It doesn’t check the system for equivalence or other errors and would need to be re-written for a different use case. But what I hope it does show is that the FHIR way of doing things has value even when you don’t use all the parts. And by using the ConceptMap there’s a path forwards to a more robust solution.
But if you’re in the situation where you’re needing to do this kind of mapping in real-time as a client (eg if the data in the repository has not been normalized) then these might be acceptable limitations.
(Hopefully my terminology colleagues won’t disown me!)
Some final thoughts on architecture.
The issue with doing this on the client is that downloading all the data first is not exactly performant (though date filtering could reduce this if you were only interested in recent results). Ideally, you’d do it on the way in to the repository (using the Integration Engine in the picture above) so that the client can just query for the information it needs. That might not be feasible, and you would also need to consider how to manage updates to the ConceptMap – do you need to ‘re-code’ all the data in the repository when the mapping changes?
One other possibility could be to use a query that specifies multiple ‘or’ parameters as discussed in the spec, and have the server do the work. You could use the ConceptMap to locate all the known system/code pairs for the specific observation you are after (a variation on the hash we used above). I’ve not tried it, but it ought to work.
Pingback: Dew Drop – May 31, 2021 (#3454) – Morning Dew by Alvin Ashcraft