Referrals, Orders and FHIR
March 31, 2014 4 Comments
One of the resources that didn’t make the DSTU was a resource to represent Referrals – and this is something that the Working Group is starting to address. However, the concept of referrals is something that crosses a number of concepts in FHIR, so I thought I’d make a few notes here before we get started. (and to give credit where it is due, I’ve had some pointers from Lloyd about the best fit within FHIR – I take responsibility for the errors!.)
Lets start by thinking what we mean by a referral – and what we would expect of a system managing referrals.
Fundamentally, referrals are a formal way of asking some other person to become involved in a patients care. A couple of examples:
- A primary care clinician (ambulatory care) has a patient with severe osteoarthritis and refers her to an Orthopaedic Surgeon for consideration of hip replacement.
- The same clinician sees another patient with raised HBA1c and other symptoms of diabetes and refers him to the local diabetes clinic for management.
- A patient in hospital for a routine procedure has symptoms suggestive of angina, and is referred to the Cardiac team for assessment.
- A patient is referred for physiotherapy after a stroke.
And there are lots of other examples of course (and I’ve glossed over some important things like responsibility for care).
So there are a number of ‘parts’ to the referral:
- There’s the general workflow stuff – there’s a sender and a recipient. It’s about someone (and that could be the sender in a self referral for that matter). The sender wants to know that the referral was received, and is being actioned.
- Then there’s more specific workflow that’s related to referral management. It’s common for multiple people to examine a referral – to triage it, put it in waiting lists, create appointments, and possibly re-direct it to other recipients. One referral might lead to another being made or to other orders (like radiology and laboratory investigations) being made. The sender should be aware of all these activities. This workflow can be specific to the recipient.
- There’s clinical information about the referral – what is the reason for the referral. What is the urgency (from the view of the sender/patient). What are the expectations of the sender. What is the clinical information that is directly pertinent to the referral (such as the raised HBA1c in the example above).
- And finally there’s the other clinical content that is not (perhaps) directly related to reason for referral, but is nevertheless important that the recipient know about. Usual medications, co-morbidities and allergies are examples of common clinical information that are almost always included in referrals regardless of the reason.
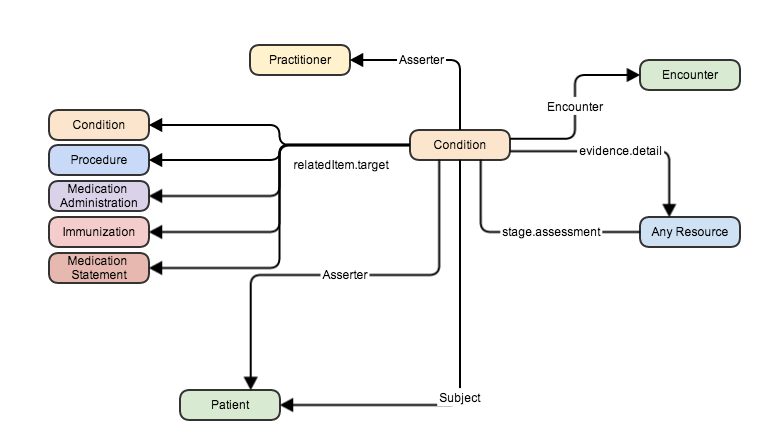
In FHIR, there are already a number of resources that manage some of these (and we hate duplication don’t we?).
There’s the Order and the OrderResponse resources that are intended to manage the workflow aspects of healthcare. If we have workflow requirements that are not met by these resources, then we should enhance them rather than duplication in our referral. (For example, a likely requirement is going to be the ability for one referral to reference another – we might want to know all the actions that were associated with a referral for costing purposes – so we might want a ‘relatedTo’ reference on an Order).
And we often think of a referral as if it were a document – in fact, in manual systems a referral is often written on a predefined template supplied by the recipient to ensure they receive the information they need to properly manage the referral. So we have the Questionnaire as a mechanism for defining that template, and the Composition if we do want to represent the referral as a formal, signed & asserted document.
And if we do go down a document paradigm, then we might want to use the DocumentReference resource as a way being able to refer to the document (perhaps we wish to display the referral with other documents in the patient record, or find similar/related referrals)
And finally there are all the clinical resources that may be included.
(Which of these resources are actually needed in any specific implementation will depend on the overall system design and architecture, but we do want to be sure that they have been designed to work together and not overlap in terms of functionality.)
So what belongs in the referral resource?
Well, as a strawman proposal lets start with:
- Sender, Patient and recipient. These are going to be duplicated in Order, but they are fundamental to a referral and so probably belong here as well. (And both DiagnosticOrder and MedicationPrescription which are similar have them, so we’re in good company).
- The reason for the referral. This could be a CodeableConcept or a string – we possibly want both, one for analysis and automated management and the other for humans (though the CodeableConcept has a text property, so a separate property may be overkill)
- Details of the referral. Clinicians commonly like narrative in a referral.
- The Priority and Urgency
- The actions we wish the recipient to perform. This might be a ‘please see and advise’ through to a ‘please perform this action’
- Supporting clinical information. Likely the clinical impression that led to the referral will be mentioned in the details – here is where the other important stuff like medications and co-morbidities can go.
- Attachments.
- Possibly a direct link to a Careplan resource since careplans can indicate when a referral is required (as can a Protocol – when we have one).
Lets finish this off by working through a real scenario – with a given architecture – and see how all this might work. Note that this is only one possible design…
We’ll go with a document based metaphor and assume there is a document repository that can hold the referral and the referral templates, and an orders management system that holds the Order resource. These could be native FHIR servers, or existing components with a FHIR façade.

- The sender locates and downloads the questionnaire resource that has the referral requirements of the recipient
- The sender assembles a document that contains the referral resource, a composition and the clinical data plus attachments. The document is submitted to the registry/repository (there is probably a DocuemntReference resource in there as well).
- The sender creates a Order which has a reference back to the referral document and submits that to the Orders Management system
- The recipient has a ‘pub/sub’ feed from the Orders management, and so retrieves the order and from that the reference to the referral document.
- They download the document (Or, hopefully, process it ‘in place’).
- Over time, the recipient performs whatever processing is required, creating OrderResponse resource as appropriate. The sender has a pub/sub feed monitoring those resources and so is aware of the status of the referral at any time. (And can make direct queries at any time).
Although not explicit, because Referral and Order are in repositories, other authorised people – including the patient – are able to review the progress at any time.
So to sum up, we’ve got a fair bit of work to do – but a lot of the bits are in place, and the art is going to be deciding what should go where!



Recent Comments